Simple Made Inevitable: The Economics of Language Choice in the LLM Era

Two years ago, I wrote about managing twenty microservices at Qantas with a small team. The problem was keeping services in sync, coordinating changes across system boundaries, fighting the entropy of a codebase that grew faster than our ability to reason about it.
Many years before my time, someone had chosen Clojure to build these systems. I suggested we add Polylith - this was a powerful combination because it enabled us to attack that "entropy" directly. Composition over coordination. Data over ceremony. Simplicity over familiarity.
I described it at the time as a "fight against accidental complexity" - the stuff that isn't the problem itself, but the overhead imposed by our tools and processes. The stuff that accretes.
Fast forward to today - I've been watching LLM coding agents struggle with the exact same fight, and I think the choice of language matters far more than most people realise.
Not less. More.
I've used Clojure for a decade, and I'm biased. But I think the economics have shifted in ways that make my bias look less like preference and more like - well, let's call it a "fortunate capital allocation".
The distinction that matters
Fred Brooks drew the line in 1986. In "No Silver Bullet," he separated the difficulty of software into two categories: essential complexity - fundamental to the problem, irreducible - and accidental complexity - imposed by our tools, languages, and processes.
Brooks argued that no tool would deliver an order-of-magnitude improvement because most of programming's difficulty is essential. But he also argued that accidental complexity was the only part amenable to radical improvement.
Rich Hickey picked up that thread and built a programming language around it (Clojure).
In his 2011 talk "Simple Made Easy," Hickey drew a distinction that the industry has spent fifteen years trying to ignore: the difference between simple (objectively unentangled, not braided together) and easy (familiar, near to hand, comfortable). The industry systematically confuses the two. We choose languages because they're easy - because the syntax looks familiar, because we can find developers on LinkedIn, because there are ten thousand Stack Overflow answers for every error message.
Not many people choose languages because they're simple.
Hickey's word for accidental complexity is "incidental." As he puts it: "Incidental is Latin for your fault."
He catalogued the sources with uncomfortable precision. State complects everything it touches. Objects complect state, identity, and value. Methods complect function and state. Syntax complects meaning and order. Inheritance complects types. Every one of these entanglements is a source of accidental complexity that has nothing to do with the problem you're trying to solve.
Clojure was designed to avoid these entanglements. Immutable data by default. Plain maps instead of class hierarchies. Functions instead of methods. Composition instead of inheritance. It was, and is, a language that optimises for simplicity over ease.
For fifteen years, the response has been: "Sure, but the learning curve.", or "Sure, but we can't hire Clojure developers, it's too niche."
And there it is. The objections that no longer hold.
The learning curve is dead
Nathan Marz recently described building a complex distributed system with Claude Code using Rama, a Clojure framework. Claude absorbed the framework's patterns through a few corrections and some documentation, and then wrote load modules, transaction handlers, and query topologies fluently.
Marz's conclusion is worth reading carefully:
"If AI can absorb a framework's semantics quickly, then the right framework to choose is the one with the best actual abstractions - the one that eliminates the most accidental complexity - regardless of how 'easy to learn' it is for a human picking it up on a weekend. Developer familiarity stops being the dominant selection criterion."
Read that again. Developer familiarity stops being the dominant selection criterion.
Wes McKinney - the creator of pandas, a developer who knows something about language ecosystems - demonstrates this from the other direction. He writes in his recent essay "The Mythical Agent-Month" that he "basically does not write code anymore, and now writes tons of code in a language (Go) I have never written by hand."
The barrier to entry for all languages has collapsed. An LLM doesn't look at Clojure's parentheses and feel intimidated. It doesn't need a weekend tutorial. It doesn't care whether the syntax resembles what it learned in university. The "easy" axis - familiarity, comfort, prior experience - has been zeroed out.
What remains is the "simple" axis. The intrinsic quality of the abstractions.
Thinking like an economist: the learning curve was always a switching cost, not a measure of the language's value. It's easy to confuse the price of entry with the value of the asset. Now, LLMs have driven that switching cost toward zero. What's left is the underlying return on investment - and that's where Clojure was built to compete.
The "Brownfield barrier"
McKinney's essay contains what I think is the most important observation about LLM-assisted development written so far:
"I am already dealing with this problem as I begin to reach the 100 KLOC mark and watch the agents begin to chase their own tails and contextually choke on the bloated codebases they have generated."
He calls this "technical debt on an unprecedented scale, accrued at machine speed."
Stop me if you've heard this one before. Systems grow and age, they accrete, they accumulate stuff. The accidental complexity compounds until the codebase becomes too large and too tangled for anyone (human or machine) to navigate effectively. I described this at Qantas as a problem of coordination overhead and context-switching costs. McKinney is describing the same phenomenon, accelerated by an order of magnitude.
The mechanism is straightforward. LLMs are, as McKinney puts it, "probably the most powerful tool ever created to tackle accidental complexity." They can refactor, write tests, clean up messes. But they also generate new accidental complexity as a byproduct: "large amounts of defensive boilerplate that is rarely needed in real-world use," "overwrought solutions to problems when a simple solution would do just fine."
Brooks predicted this. His "No Silver Bullet" argument is that agents are brilliant at accidental complexity but struggle with essential design problems - and worse, they can't reliably tell the difference. They attack the accidental complexity with extraordinary capability while simultaneously producing more of it.
This is where language choice becomes a capital allocation decision with compounding returns. The brownfield barrier isn't about whether an LLM can write Python or Go or JavaScript - of course it can. It's about what happens at scale. The cost of a language choice isn't visible in the first ten thousand lines. It's visible at a hundred thousand, when the compounding effects of accidental complexity become the dominant cost.
Classic economics where marginal cost curves that look flat early and then inflect sharply.
Why Clojure pushes the barrier further
Clojure attacks this "brownfield barrier" from multiple directions simultaneously, and the effects compound.
Token efficiency
Martin Alderson's analysis of Rosetta Code tasks across nineteen popular languages found Clojure to be the most token-efficient. Not by a trivial margin:
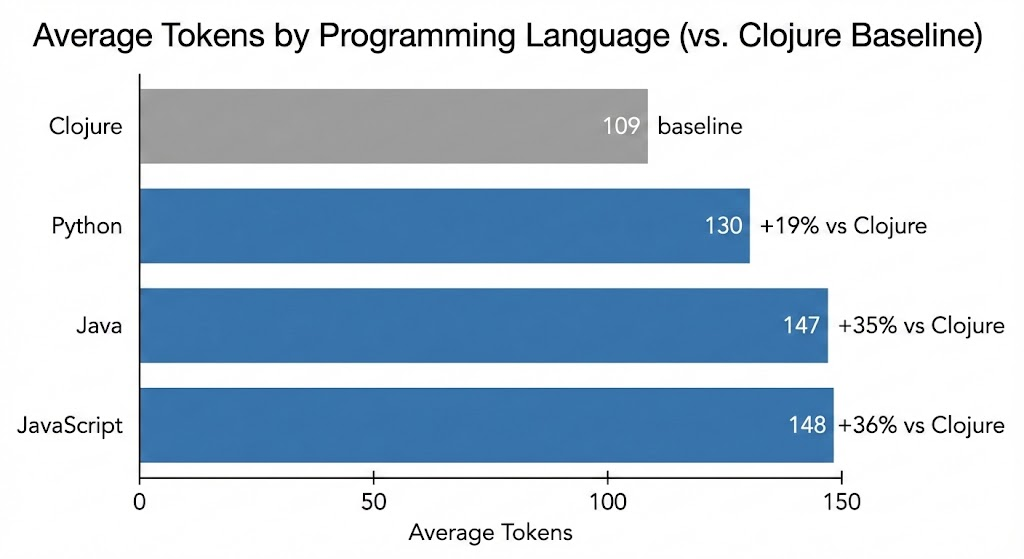
These aren't obscure comparisons. Python, JavaScript, and Java are the three most used languages in the world. Clojure expresses the same logic in roughly a fifth fewer tokens than Python and a third fewer than JavaScript or Java.
Why does this matter? Because context windows are a hard constraint, and they degrade non-linearly. Research from Stanford and Berkeley shows that LLM performance drops by more than 30% when relevant information falls in the middle of the context window. Factory.ai found that models claiming 200,000 tokens of context become unreliable around 130,000 - a sharp cliff, not a gentle slope. Anthropic describes context engineering as a first-class discipline, noting that "structured data like code consumes disproportionately more tokens."
If 80% of a coding agent's context window is code - reads, edits, diffs - then Clojure's 19% token advantage over Python translates to roughly 15% more room for actual problem context. Against JavaScript or Java, it's nearly 30% more room. Over a long session with multiple file reads and iterative edits, this compounds. The agent that runs out of useful context first loses.
And these are just the token-level numbers. At the program level, the difference is starker. Anthony Marcar at WalmartLabs reported that "Clojure shrinks our code base to about one-fifth the size it would be if we had written in Java." A fifth. McKinney's 100 KLOC brownfield barrier in Go could be structurally unreachable in Clojure - not because the agent is smarter, but because there's less accidental complexity for it to choke on.
Immutability eliminates defensive boilerplate
McKinney specifically identifies that agents "tend to introduce unnecessary complexity, generating large amounts of defensive boilerplate." Null checks. Defensive copies. Synchronisation guards. Clojure's immutable data structures eliminate entire categories of this bloat. The agent literally cannot generate certain kinds of accidental complexity because the language makes it unnecessary.
As Hickey puts it: "Values support reproducible results. If you define a function in terms of values, every time you call that function with the same values, will you get the same answer? Yes."
An LLM reasoning about immutable code doesn't need to track when a variable was modified or by whom. It can reason algebraically: this function takes X and returns Y. Full stop. No temporal reasoning required. That's fewer balls to juggle - and as Hickey reminds us, even the best juggler in the world maxes out at about twelve.
Data orientation scales linearly, not combinatorially
Stuart Halloway made this point devastatingly in his talk "Running With Scissors." When you use typed structs or classes, "all of your data manipulation scissors are gone. You do not have generic data any more. Each one of these structs requires its own custom special scissors to manipulate it."
With Clojure's maps, the LLM learns one toolkit - assoc, merge, select-keys, update, get-in - that works on all data. With an object-oriented language, the LLM must learn a different API for every class. That's the difference between O(n) and O(n^2) in what the agent must hold in context. As the codebase grows, this gap widens.
The REPL closes the feedback loop
Halloway's formulation is the best I've seen: "REPL + Functional = faster bricks. Things that you understand how they are going to work. They always work the same way, and you can compose them to build your system." And the dark corollary: "REPL + imperative = faster spaghetti. If you are a net negative producing developer and we speed you up... we have just made things worse."
An LLM agent at a Clojure REPL can evaluate any expression in the running system, inspect the result, and adjust. No compilation step. No build system. No waiting. The feedback loop is as tight as it gets.
I should note that the major coding agents today - Claude Code, Codex, Cursor - don't use REPLs. They use file-edit, compile-or-test, read-errors, iterate loops. The industry has implicitly chosen compiler-style feedback. This is worth engaging with honestly.
But the evidence is more nuanced than it appears. Research on CodePatchLLM (KDD 2024) found that compiler feedback improves Java and Kotlin code generation by 45% - but provides zero improvement for Python, because there's no compiler feedback to give. Dynamic languages get nothing from the compile loop. Replit Agent, notably, does use a REPL-based verification system and reports results three times faster and ten times cheaper than previous approaches.
And Halloway's distinction cuts precisely here. A Python or JavaScript REPL creates exactly the temporal coupling problem that critics identify - mutable state accumulating in the session, order-dependent evaluation, "faster spaghetti." Clojure's REPL evaluates expressions that return immutable values. Data in, data out. No temporal coupling. The REPL provides richer feedback than a compiler - actual return values, not just "compiled" or "didn't" - while Clojure's immutability means it doesn't create the stateful mess that imperative REPLs do. Clojure-MCP bridges the remaining gap: the agent writes to files and validates in the REPL. Bille reported tasks completing in hours instead of days.
The Go irony
There's a revealing irony buried in the data. McKinney chose Go for his new projects - a language famous for its simplicity. He writes it via LLM agents and hits the brownfield barrier at 100 KLOC.
But Go's simplicity is an easy simplicity in Hickey's sense. It's familiar. It's readable. You can hire for it. It achieves this through verbosity: explicit error handling on every function call, no generics until recently, no macros, no metaprogramming. For human programmers, this verbosity is a feature - it makes code predictable and reviewable.
For LLM agents, it's a tax.
Alderson's data shows Go as one of the more token-inefficient popular languages. Every if err != nil { return err } consumes tokens that could be used for problem context. The language chosen for human simplicity creates machine problems. Go is optimised for human-readable code; Clojure is optimised for expressing ideas with minimal ceremony. The LLM era rewards the latter.
Is verbosity a benefit?
There's a seductive counter argument here: that Go's verbosity actually helps the model reason. Verbose output as chain-of-thought scaffolding - the same mechanism that helps LLMs solve maths problems. More tokens, more thinking.
It's wrong, and the architecture tells you why.
Modern reasoning models - o1, o3, Claude with extended thinking - do their reasoning in hidden tokens that are discarded after generation. The thinking has already happened before the model outputs a single character of code. Go's if err != nil { return err } is output tokens, not reasoning tokens. It doesn't expand the model's thinking budget. It spends the context budget.
The empirical evidence is decisive. Research presented at ICML 2025 found that generating code first, then reasoning, yielded a 9.86% improvement over the traditional reason-then-code order. If verbose output were serving as reasoning scaffolding, the opposite should be true. The Token Sugar paper (ICSE 2025) systematically compressed high-frequency verbose patterns - exactly the kind Go generates - and achieved up to 15.1% token reduction with near-identical correctness scores. If the boilerplate were contributing to correctness, removing it would degrade performance. It didn't.
Worse, context dilution research shows that repetitive, low-information tokens actively harm performance by diluting the model's finite attention budget - accuracy drops of 13.9 - 85%.
Every if err != nil repeated fifty times across a codebase isn't scaffolding. It's noise competing for the model's attention with the actual problem.
Some counter-arguments
Let's assess some of the arguments against my thesis above - some of which are genuinely strong.
LLMs are measurably worse at Clojure
This is the big one. The FPEval benchmark found that GPT-5 generates code with 94% imperative patterns in Scala, 88% in Haskell, and 80% in OCaml. LLMs don't just write worse functional code - they write imperative code disguised as functional code, and the prevalence of non-idiomatic patterns actually increases alongside gains in functional correctness. Jack Palvich's Gemini experiments across twenty-four languages found that "the Lisps suffer from paren mis-matches and mistakes using standard library functions." The MultiPL-E benchmark shows performance correlating with language popularity. And the "LLMs Love Python" paper found that models default to Python in 93-97% of language-agnostic problems.
This is real. I'm not going to pretend it isn't.
But notice what's actually being measured. These benchmarks measure whether the LLM can generate a correct function in language X. They don't measure whether the resulting system - the codebase at 50 or 100 KLOC - is maintainable, navigable, or tractable for future agent sessions. "Better at generating Python" and "Python generates better systems" are different claims.
And the FPEval result is, if you squint, actually evidence for the thesis. If LLMs default to imperative patterns even when writing in functional languages, then the language's constraints matter more, not less. Clojure's immutability isn't a suggestion - it's a default. The language itself acts as a guardrail. An LLM generating Clojure has fewer ways to produce the kind of stateful, tangled code that compounds into the brownfield barrier. You can't mutate what the language won't let you mutate.
The parenthesis problem is real but solvable. Julien Bille documented his experience with Clojure-MCP: initially "simple things took way too long" and the AI was "unable to get parentheses right." But after integrating s-expression-aware tooling, "the agent experience got much better" and "it goes a LOT faster to write good code solutions." The parenthesis issue is a tooling gap, not a fundamental limitation.
And the training data argument is about the present, not the structure. Models are improving rapidly. The accidental complexity argument is about permanent properties of the language. One is a snapshot; the other is a trajectory.
And the snapshot is less damning than it looks. Cassano et al.'s MultiPL-E study (IEEE TSE, 2023) found that model perplexity - how uncertain the model is when predicting the next token - is not strongly correlated with the correctness of generated code. Codex's perplexity (uncertainty) was highest for JavaScript and TypeScript, yet it performed best on those languages. Some niche languages performed as well as popular ones. Training data volume is not the determinant the gravity well argument assumes.
MultiPL-T (OOPSLA, 2024) went further: fine-tuning on automatically translated data closed the gap entirely. Lua exceeded base Python performance after targeted fine-tuning. Julia saw 67% relative improvement. The gap isn't a permanent feature of the landscape - it's bridgeable engineering.
There's also the question of cross-lingual transfer. Research on scaling laws for code found that training on one language improves performance on related languages. Clojure sits on the JVM. The massive Java training corpus isn't irrelevant - it's a shared ecosystem, shared libraries, shared concepts.
Static type systems provide a feedback loop Clojure lacks
Also strong. Research from ETH Zurich (PLDI 2025) shows that type-constrained decoding reduces compilation errors by more than half and increases functional correctness by 3.5-5.5%. TypeScript advocates report 90% reductions in certain bug categories. Rust's strict compiler creates tight generate-compile-fix loops.
I'll grant it: types help LLMs get individual functions right. The evidence is clear.
But types also create coupling. As Hickey argues: "Statically typed languages yield much more heavily coupled systems. Flowing type information is a major source of coupling in programs." Types help the LLM write correct function A. But they also create structural dependencies between A, B, C, and D that make the system harder to reason about as it grows. The question is which effect dominates at scale - and McKinney's brownfield barrier suggests that system-level coupling is the bigger problem.
Clojure offers a middle path. Spec and Malli provide optional schema validation - type-like constraints when you want them, without the token overhead and coupling when you don't. And the REPL provides a runtime feedback loop that is arguably faster than a compilation cycle: the agent evaluates an expression, sees the result or the error, and corrects immediately.
This is how I'm leveraging Clojure (and Polylith) while I'm building AXONLORE - components with Malli function schema on every interface, enforced at testing and development time.
It's also worth noting Alderson's data: Haskell and F#, typed languages with strong inference, are nearly as token-efficient as Clojure. If the type system feedback loop is your priority, those are better choices than TypeScript or Rust, both of which are significantly more token-heavy. But Haskell and F# have their own ecosystem and adoption challenges. There's no free lunch.
The ecosystem is small and hiring is hard
This is the objection I've spent a decade fielding, and it cuts differently now. If developers aren't writing code by hand, "knowing Clojure" matters less than having good design taste - which McKinney identifies as the scarce resource: "Design talent and good taste are the most scarce resources, and now with agents doing all of the coding labor, I argue that these skills matter more now than ever."
The hiring bottleneck shifts from language fluency to architectural judgement. Clojure developers tend to be more senior and more experienced. That's exactly the profile McKinney says will thrive.
And on ecosystem: Clojure has access to the entire JVM ecosystem through Java interop. The "small ecosystem" argument was always about discoverability for humans - and LLMs don't need Stack Overflow.
Stability as signal
There's one more structural advantage worth noting. Hickey argued in his talk "Spec-ulation" that "dependency hell is not a different thing than mutability hell. It IS mutability hell. It is just at this scale."
LLMs are trained on vast codebases. Breaking changes in a language ecosystem mean that the training data contains conflicting information about the same names. clojure.core/map has meant the same thing for seventeen years. Compare that with Python 2 versus 3, React class components versus hooks versus server components, Angular.js versus Angular, or JavaScript's shifting parade of module systems.
Stability means consistent training signal. Consistent signal means more reliable output. This isn't a flashy advantage, but it's a durable one. When an LLM generates Clojure, it's drawing on seventeen years of consistent semantics. When it generates React, it's navigating a minefield of deprecated patterns, version-specific APIs, and conflicting idioms from different eras of the framework.
Erik Bernhardsson built a tool called Git of Theseus - after the philosophical paradox
about the ship whose planks are replaced one by one until nothing original remains. Run it
against a Git repository and it shows you what percentage of each year's code survives into
the present. The half-life of a line of code in Angular is 0.32 years. In Rails, 2.43
years. In Linux, 6.6 years. Linux's longevity, Bernhardsson notes, comes from its
modularity - drivers and architecture support scale linearly because they have well-defined
interfaces. Each marginal feature takes roughly the same amount of code. Bad projects, on the other hand, scale superlinearly - every marginal feature takes more and more code.
Rich Hickey published code retention charts for Clojure in his ACM paper "A
History of Clojure." The Clojure chart is nearly flat - almost all code from every release
survives into the current version.
For an LLM, this is the difference between signal and noise. Every breaking change in a
language's history creates conflicting training data - the same function name meaning
different things in different eras. Every renamed API, every deprecated pattern, every
framework migration is a source of confusion that the model must navigate
probabilistically. Clojure's stability means the probability mass is concentrated. There's
one way to use map, one way to use assoc, and that's been true since 2007. The model
doesn't have to guess which era of the language it's generating for.
The Investment question
I'm not arguing that Clojure is perfect. I'm arguing that the selection criteria have changed, and we haven't updated our decision-making frameworks to match.
The industry has - until now - selected languages for human convenience: familiar syntax, large hiring pools, abundant tutorials, massive ecosystems of libraries with thousands of GitHub stars. These were rational criteria when humans wrote the code. They optimised for the dominant constraint.
But the dominant constraint has shifted. Humans increasingly don't write the code. Machines do. And machines have different constraints: context windows, token efficiency, the ability to reason about entangled state, the compounding cost of accidental complexity at scale.
The question you should ask is: what's the time horizon?
If you're building a prototype that needs to work next week, use Python. The LLM is better at it today, the ecosystem is massive, and the brownfield barrier is someone else's problem (perhaps future you?). This is the savings account - safe, familiar, reliable returns.
If you're building something you plan to maintain for five years, the calculation changes. The language that generates the most maintainable codebase - the one that produces the least accidental complexity per unit of work, that fits more meaning into fewer tokens, that constrains the agent away from its worst impulses - that's the language with the higher compounding return. Even if the individual function quality is lower today.
There's also an uncomfortable possibility lurking here: that the best language for LLMs might not be any existing language at all. Perhaps we'll see languages designed from scratch for machine cognition - token-efficient, structurally regular, with built-in verification. But if we're choosing among what exists today, the properties Hickey optimised for seventeen years ago - simplicity, immutability, data orientation, homoiconicity, stability - happen to be exactly what machines need.
There's an obvious outcome though, at least while humans still choose the tools. Developer preference, hiring committees, LinkedIn keyword searches - these are powerful forces, and they don't evaporate just because the code is being written by a machine. The industry
has spent decades optimising for human convenience, and switching costs are real. It's entirely possible we stick with the popular languages for another decade, not because they're the most efficient allocation of capital, but because the humans holding the cheque books are comfortable with them.
My bet is on the other outcome. An industry that chose languages for humans will eventually notice that the humans have left the keyboard. And when the constraint you optimised for no longer binds, the economics eventually catch up. They always do.